What is Edge [and Fog] Computing and How is it Redefining the Data Center?
We all have heard of this Cloud. In its most general terms, cloud computing enables companies, service providers and individuals to provision the appropriate amount of computing resources dynamically (compute nodes, block or object storage and so on) for their needs. These application services are accessed over a network—and not necessarily a public network. Three distinct types of cloud deployments exist: public, private and a hybrid of both.
The public cloud differentiates itself from the private cloud in that the private cloud typically is deployed in the data center and under the proprietary network using its cloud computing technologies—that is, it is developed for and maintained by the organization it serves. Resources for a private cloud deployment are acquired via normal hardware purchasing means and through traditional hardware sales channels. This is not the case for the public cloud. Resources for the public cloud are provisioned dynamically to its user as requested and may be offered under a pay-per-usage model or for free (e.g. AWS, Azure, et al). As the name implies, the hybrid model allows for seamless access and transitioning between both public and private (or on-premise) deployments, all managed under a single framework.
However, there exists a problem: cloud deployments tend to hide behind a “cloud” of networks and in some remote data center. Accessing those resources (via a mobile, notebook or IoT device) introduces latency. A new computing paradigm was defined to address this problem: Edge Computing. Edge computing brings the data storage and compute processing closer to the location where it is needed; that is, it moves data, applications and services away from points of centralization to areas closer to where the data is being generated and consumed (users, digital platforms, etc.). Another way of saying this is: edge computing is computing that’s done at or near the source of the data being generated/collected and not relying on the cloud to do the same amount of work for it. The cloud does not disappear in this paradigm. In fact, it is coming closer to you and your device(s).
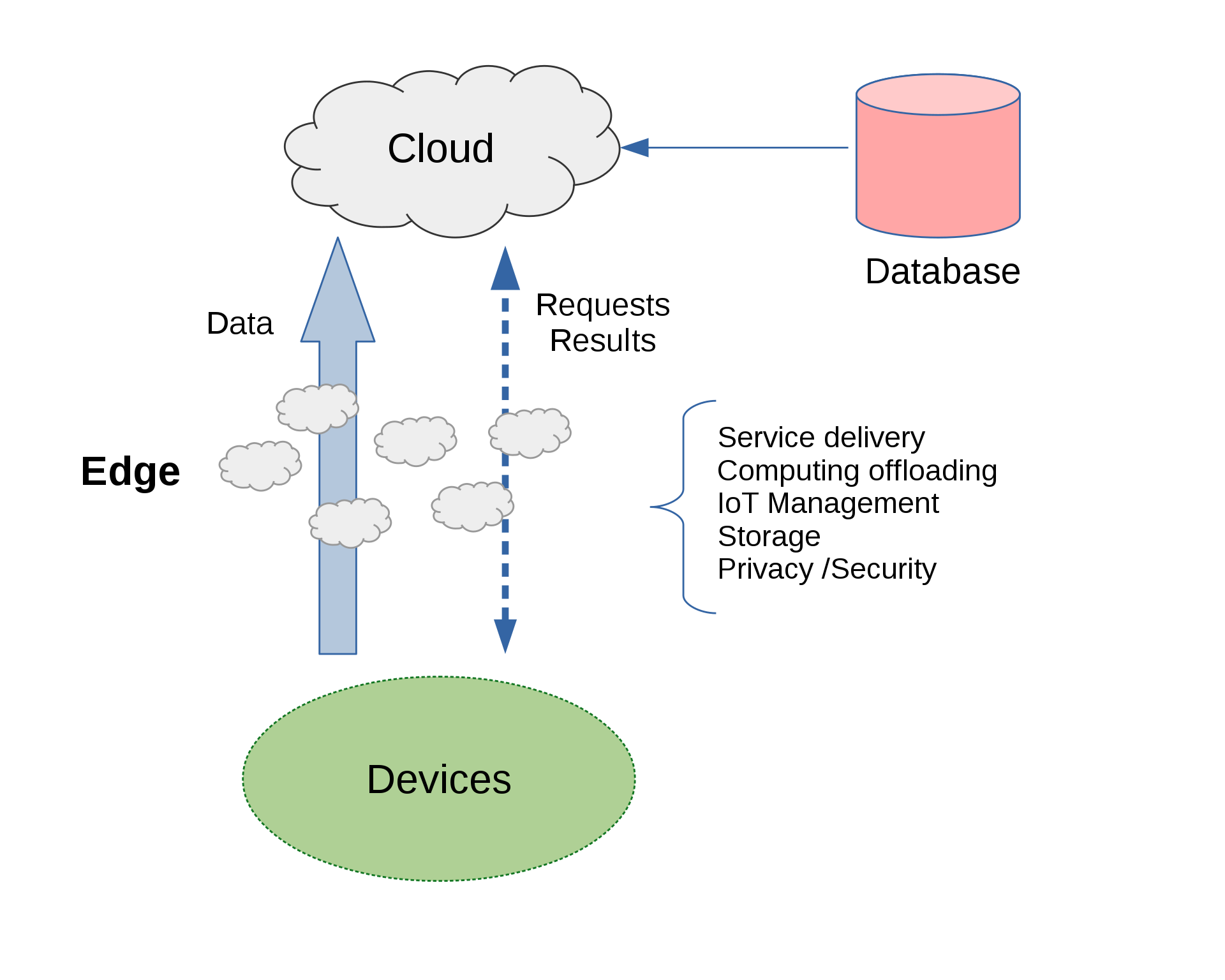
There are benefits to this new approach:
Minimal (or reduced) Latency – when the compute lives closer to the data being collected, less time is needed to access the desired data sets and less data congests the rat’s nest of networking pipes. All of a sudden, we are talking about Quality of Service (or QoS), again.
Simplified Maintenance – when the compute lives closer to the data being collected, maintaining, debugging and troubleshooting a problem from its source immediately becomes less complicated.
Cheaper Cooling – when data processing is offloaded from those more complex data centers, the monthly cost in electricity used in cooling and data processing is reduced.
There are also challenges:
Security (and Privacy) – the distributed nature of the edge computing paradigm introduces a shift in security schemes used in cloud computing. Data should and needs to be encrypted. Furthermore, edge nodes may also be resource constrained devices, limiting the types of security methods used.
Scalability – how does one scale? Device(s) and the network in which they connect to are quite dynamic and diverse. This lack of consistency can and will produce unpredictable results.
And Reliability – ensuring that services remain alive, even after failures is further complicated. How does failover work? If the service or node is disabled or becomes unreachable, how is the user or device to continue accessing said service without interruption? The services at “the edge” need to account for such disruptions or failures and either alert the parties that matter or gracefully handle the failure without a noticeable impact on its user.
—
Now, what is this Fog Computing? And how does it relate to edge computing?
Fog computing (or fog networking) is an architecture that uses edge devices to carry out a substantial amount of the computation and storage. It enables computing services to reside at the edge of the network as opposed to servers in a data center. Unlike edge computing, fog computing brings computing at a closer proximity to the end-user; thereby, further reducing latencies. As more devices are fitted with more powerful processors and ample of local storage, fog computing becomes more of a reality.
—
While IoT nodes are closer to the action, they do not have the computing and storage resources to perform analytics and machine learning tasks. On the other hand, Cloud servers have the horsepower, but are too far away to process data and respond in timely manner. Edge [and Fog] computing bridges the two technologies to reduce access times and bring the compute closer to you.