The Next Stage of Flash Storage: Computational Storage
Throughout my career in the data storage industry, I have seen many technologies come and go. Some of the more recent technologies to disappear include Fibre Channel over Ethernet (FCoE) and the Kinetic drives (although the Kinetic concept may be reborn as the direct-to-Ethernet SSD). That aside, it is apparent that the NVMe (or Non-Volatile Memory Express) is here to stay and will soon supplant Serial Attached SCSI (SAS) and Serial ATA (SATA) Flash media. It makes sense though. NVMe was designed from the ground up to be performant; that is, I/O can be parallelized to/from the device. Another positive: the command set is more lightweight than the ones used by its SAS/SATA cousins.
To learn more about NVMe, read my FREE e-book – Data in a Flash: Everything You Need to Know About NVMe.
The NVMe technology lives on top of the PCIe topology and much closer to the CPU. In fact, when an operating system’s NVMe device driver detects a new NVMe device, it will create multiple I/O Submission Queues (SQ) that scale to the number of active cores present on the server (typically one-per-CPU). This is what enables the parallelization feature. The driver will also create a single Completion Queue (CQ) to handle the completion of I/O requests [which will eventually propagate status back up the I/O stack and to the calling application]. As one would expect, with enough NVMe drives installed and enough I/O traffic hitting those same drives, the load will eventually consume the processor, to the point where the processor becomes a bottleneck. This phenomenon is a well understood one. I can even show you Linux perf trace captures [and the more visual Flamegraphs] where the application sending I/O to the drive is competing for CPU time with the NVMe device’s CQ. This alone increases I/O latency times and kills overall performance. But how does one overcome this bottleneck? The answer may be a simple one: move the application closer to the drive.
Computational Storage
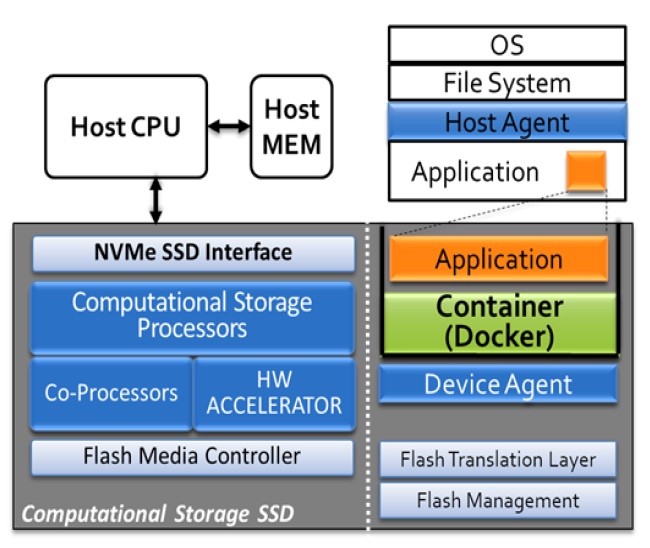
Often, the latency introduced between an application and the data it needs to access is too long, or the CPU cycles required to host that application consume too many resources on the host machine, introducing additional latencies to the drive itself. What does one do to avoid such negative impacts? Instead, one moves the application to the physical drive itself. This is a more recent emerging trend, and it’s referred to as Computational Storage.
Standing at the forefront of said technology are NGD Systems, ScaleFlux and even Samsung. So, what is Computational Storage? And, how is it implemented?
The idea is to relocate data processing into the data storage layer and avoid moving the data into the computer’s main memory (originally to be processed by the host CPU). Think about it. On a traditional system, it takes resources to move data from where it is stored, process it and then move it back to the same storage target. The entire process will take time and will introduce access latencies—even more so if the host system is tending to other related (or unrelated) tasks. In addition, the larger the data set, the more time it will take to move in/out.
To address this pain point, a few vendors have started to integrate an embedded microprocessor into the controller of their NVMe SSDs. The processor will run a standard operating system (such as Ubuntu Linux) and will allow a piece of software to run locally [typically inside a Container] on that SSD for in situ computing. Software vendors such as Microsoft are already porting key data center applications (e.g. Azure IoT Edge) to the new technology.
Now, is computational storage a trend or here to stay? Only time will tell but until then we will likely see more partners collaborate with companies such as NGD and more competitors implementing their own variations of the technology.